下面关于链表和数组的描述,错误的是( )。
当数据数量不确定时,为了应对各种可能的情况,需要申请一个较大的数组,可能浪费空间;此时用链表比较合适,大小可动态调整。
在链表中访问节点的效率较低,时间复杂度为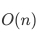 。
。
链表插入和删除元素效率较低,时间复杂度为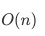 。
。
链表的节点在内存中是分散存储的,通过指针连在一起。
在循环单链表中,节点的 next 指针指向下一个节点,最后一个节点的 next 指针指向( )。
当前节点
nullptr
第一个节点
上一个节点
为了方便链表的增删操作,一些算法生成一个虚拟头节点,方便统一删除头节点和其他节点。下面代码实现了删除链表中值为 val 的节点,横线上应填的最佳代码是( )。
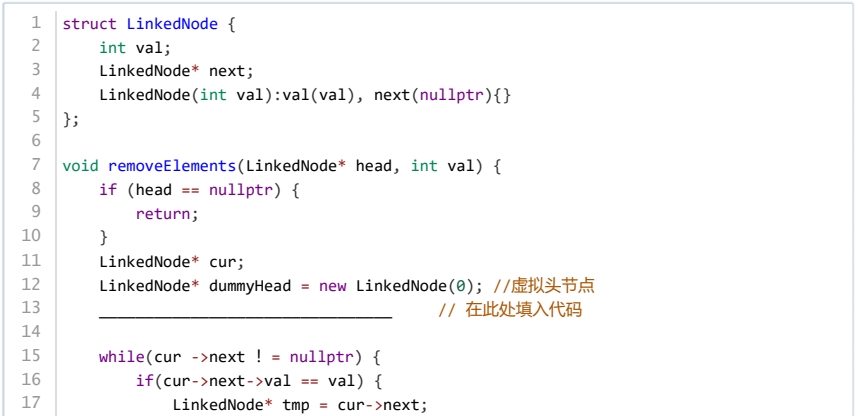
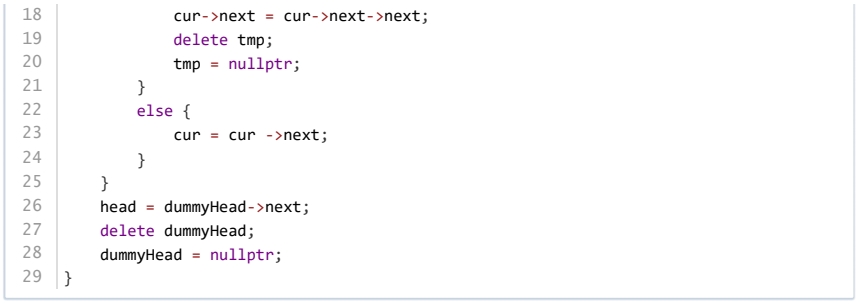
dummyHead->next = head; cur = dummyHead;
dummyHead->next = head->next; cur = dummyHead;
dummyHead->next = head; cur = dummyHead->next;
dummyHead->next = head->next; cur = dummyHead->next;
对下面两个函数,说法错误的是( )。

两个函数的实现的功能相同。
fibA采用递推方式。
fibB采用的是递归方式。
fibA时间复杂度为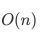 ,fibB的时间复杂度为
,fibB的时间复杂度为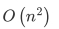 。
。
两块长方形土地的长宽分别为 和 米,要将它们分成正方形的小块,使得正方形的尺寸尽可能大。小杨采用如下的辗转相除函数 gcd(24, 36) 来求正方形分块的边长,则函数 gcd 调用顺序为( )。
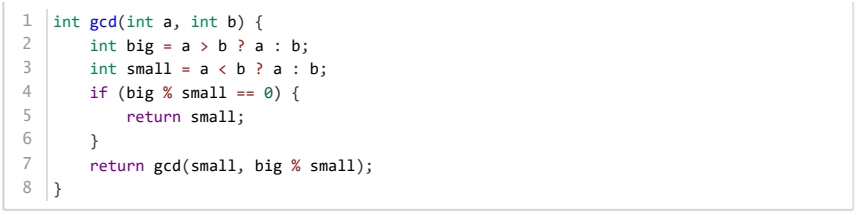
gcd(24, 36)、gcd(24, 12)、gcd(12, 0)
gcd(24, 36)、gcd(12, 24)、gcd(0, 12)
gcd(24, 36)、gcd(24, 12)
gcd(24, 36)、gcd(12, 24)
唯一分解定理表明,每个大于1的自然数可以唯一地写成若干个质数的乘积。下面函数将自然数 n的所有质因素找出来,横线上能填写的最佳代码是( )。
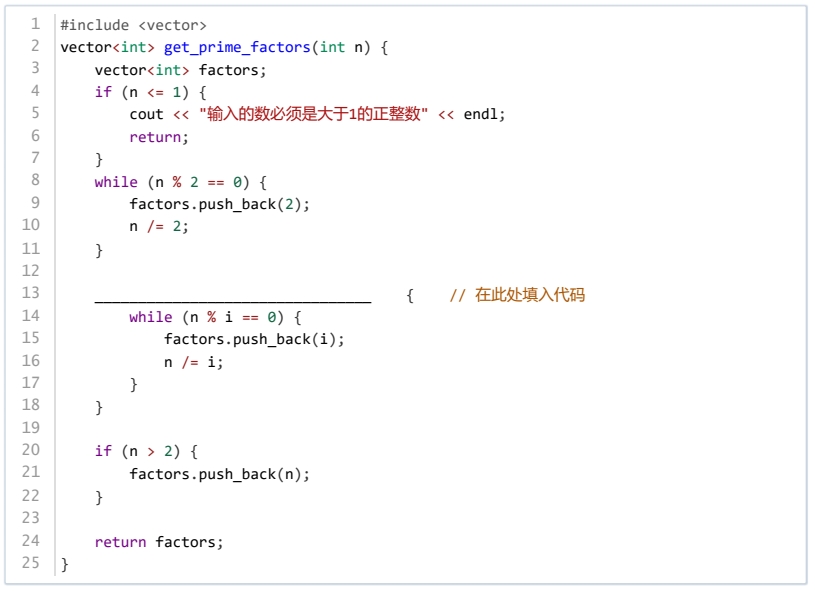
for (int i = 3; i <= n; i ++)
for (int i = 3; i * i <= n; i ++)
for (int i = 3; i <= n; i += 2)
for (int i = 3; i * i <= n; i += 2)
下述代码实现素数表的埃拉托色尼(埃氏)筛法,筛选出所有小于等于n 的素数。下面说法,正确的是( )。
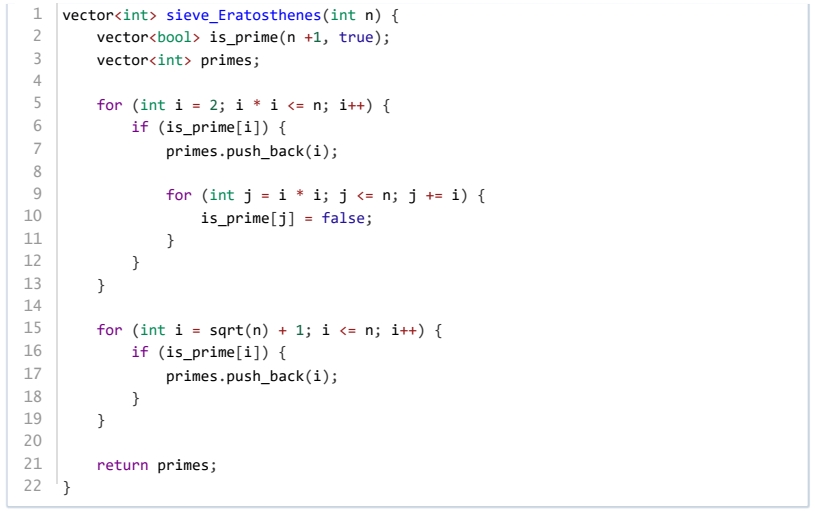
代码的时间复杂度是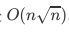
在标记非素数时,代码从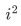 开始,可以减少重复标记。
开始,可以减少重复标记。
代码会输出所有小于等于n 的奇数。
调用函数 sieve_Eratosthenes(10) ,函数返回值的数组中包含的元素有: 2, 3, 5, 7, 9 。
下述代码实现素数表的线性筛法,筛选出所有小于等于 的素数。下面说法正确的是( )。
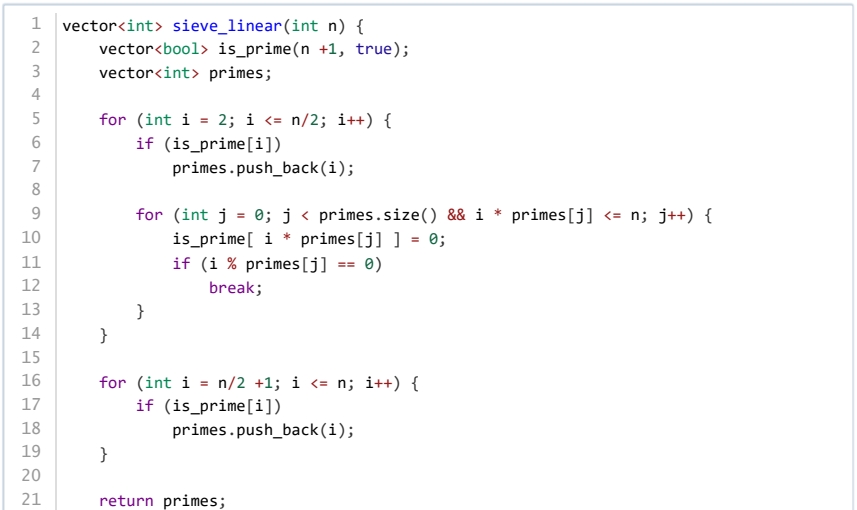

线性筛的时间复杂度是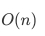
每个合数会被其所有的质因子标记一次。
线性筛和埃拉托色尼筛的实现思路完全相同。
以上都不对
考虑以下C++代码实现的快速排序算法:
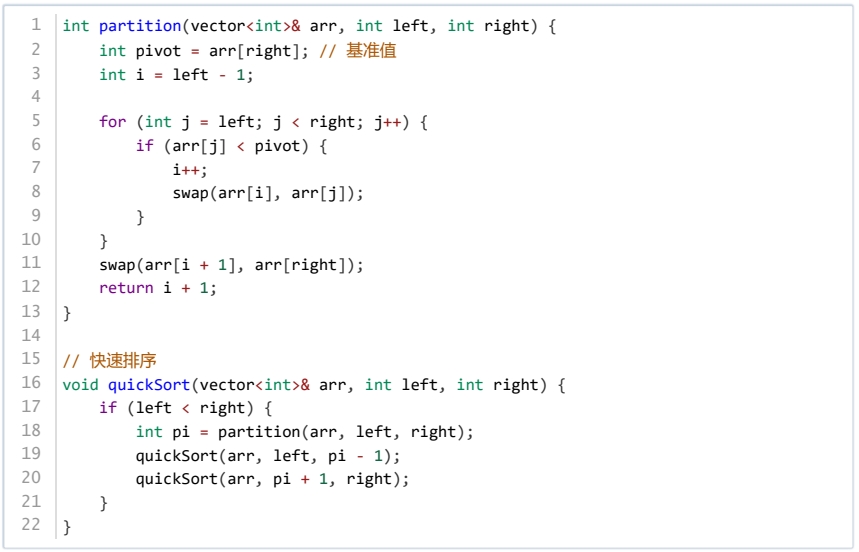
以下关于快速排序的说法,正确的是( )。
快速排序通过递归对子问题进行求解。
快速排序的最坏时间复杂度是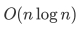 。
。
快速排序是一个稳定的排序算法。
在最优情况下,快速排序的时间复杂度是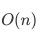 。
。
下面关于归并排序,描述正确的是( )。
归并排序是一个不稳定的排序算法。
归并排序的时间复杂度在最优、最差和平均情况下都是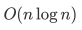 。
。
归并排序需要额外的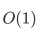 空间。
空间。
对于输入数组 {12, 11, 13, 5, 6, 7},代码输出结果为:7 6 5 13 12 11。
给定一个长度为 n的有序数组 nums ,其中所有元素都是唯一的。下面的函数返回数组中元素 target 的索引。

关于上述函数,描述不正确的是( )。
函数采用二分查找,每次计算搜索当前搜索区间的中点,然后根据中点的元素值排除一半搜索区间。
函数采用递归求解,每次问题的规模减小一半。
递归的终止条件是中间元素的值等于 target ,若数组中不包含该元素,递归不会终止。
算法的复杂度为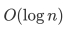 。
。
给定一个长度为 m的有序数组 nums ,其中可能包含重复元素。下面的函数返回数组中某个元素 target 的左边界,若数组中不包含该元素,则返回 −1 。例如在数组 nums = [5,7,7,8,8,10] 中查找 target=8 ,函数返回8 在数组中的左边界的索引为 。则横线上应填写的代码为( )。

right = middle - 1;
right = middle;
right = middle + 1;
以上都不对
假设有多个孩子,数组 g 保存所有孩子的胃口值。有多块饼干,数组 s 保存所有饼干的尺寸。小杨给孩子们发饼干,每个孩子最多只能给一块饼干。饼干的尺寸大于等于孩子的胃口时,孩子才能得到满足。小杨的目标是尽可能满足越多数量的孩子,因此打算采用贪心算法来找出能满足的孩子的数目,则横线上应填写的代码为( )。

result++; index--;
result--; index--;
result--; index++;
result++; index++;
关于分治算法,以下说法中不正确的是( )
分治算法将问题分成子问题,然后分别解决子问题,最后合并结果。
归并排序采用了分治思想。
快速排序采用了分治思想。
冒泡排序采用了分治思想。
小杨编写了一个如下的高精度减法函数:

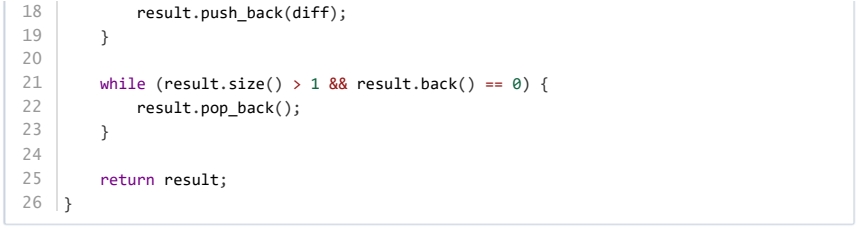
下面说法,正确的是( )。
如果数组a 表示的整数小于 表示的整数,代码会正确返回二者的差为负数。
代码假设输入数字是以倒序存储的,例如 500存储为 {0, 0, 5} 。
代码的时间复杂度为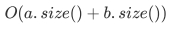
当减法结果为 0时,结果数组仍然会存储很多个元素0 。
单链表只支持在表头进行插入和删除操作。
对
错
线性筛相对于埃拉托斯特尼筛法,每个合数只会被它的最小质因数筛去一次,因此效率更高。
对
错
任何一个大于1的自然数都可以分解成若干个不同的质数的乘积,且分解方式是唯一的。
对
错
贪心算法通过每一步选择当前最优解,从而一定能获得全局最优解。
对
错
递归算法必须有一个明确的结束条件,否则会导致无限递归并可能引发栈溢出。
对
错
快速排序和归并排序的平均时间复杂度均为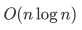 ,且都是稳定排序。
,且都是稳定排序。
对
错
快速排序的时间复杂度总比插入排序的时间复杂度低。
对
错
二分查找仅适用于数组而不适合链表,因为二分查找需要跳跃式访问元素,链表中执行跳跃式访问的效率低。
对
错
对有序数组 {5,13,19,21,37,56,64,75,88,92,100} 进行二分查找,成功查找元素 19 的比较次数是2。
对
错
递归函数每次调用自身时,系统都会为新开启的函数分配内存,以存储局部变量、调用地址和其他信息等,导致递归通常比迭代更加耗费内存空间。
对
错